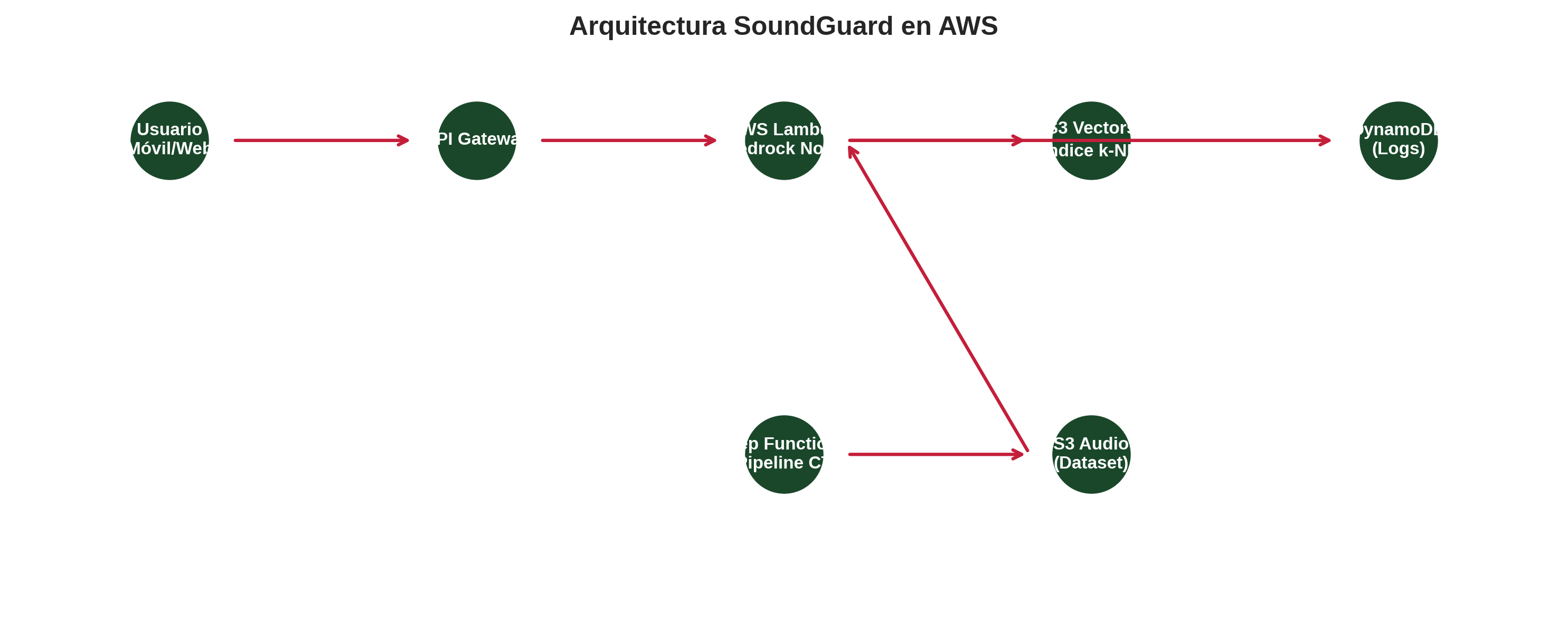
Arquitectura
Diagrama AWS, decisiones técnicas y flujo de datos serverless.
Visión de alto nivel
Audio (≤ 5 MB, ≤ 30 s)
│
▼
API Gateway HTTP API
│ POST /classify · GET /health
▼
Lambda (soundguard-dev-inference, Python 3.12)
│
├──▶ Bedrock InvokeModel ──▶ Nova Multimodal Embeddings (1024 dims)
│
├──▶ S3 Vectors query ──▶ top-k vecinos por distancia coseno
│
└──▶ DynamoDB put_item ──▶ log de la predicción
│
▼
SNS publish (sólo si is_critical y urgency == "high")Todo el path crítico es serverless: API Gateway → Lambda → Bedrock → S3 Vectors. Sin contenedores, sin máquinas, sin GPUs. La Lambda hace cold start en frío en ~1.5 s y queda caliente unos minutos.
Diagrama AWS
Decisiones técnicas clave
1. Por qué embeddings de un foundation model en vez de entrenar
Amazon Nova Multimodal Embeddings es un foundation model pre-entrenado por AWS con billones de parámetros. Ya "sabe" qué es un perro, una sirena, un motor.
Clip de audio (5 s, WAV) ─Bedrock InvokeModel─▶ Embedding (1024 dims)
"ladrido.wav" [0.12, -0.45, 0.89, ...]Esto es transfer learning aplicado: transferimos el conocimiento del modelo gigante a sonidos ambientales. Sin GPU, sin loop de entrenamiento, sin pesos que versionar.
2. Por qué k-NN en vez de un clasificador entrenado
En vez de mapear embeddings → clases con una red neuronal, hacemos votación de los k vecinos más cercanos:
Embedding nuevo ─k-NN sobre S3 Vectors─▶ Clase predicha
[0.12, ...] top-5 vecinos "dog" (4 votos)El "modelo" aquí no son pesos: es el conjunto de ejemplos (los 400 embeddings con sus etiquetas) más la regla de decisión (votación mayoritaria de los k vecinos). Esto es instance-based learning.
Ventajas para nuestro caso:
- Agregar clases nuevas = agregar ejemplos. Sin reentrenar nada.
- Explicabilidad gratis. Cada predicción viene con sus vecinos visibles.
- Cero costo de entrenamiento. Solo costo de embedding + storage vectorial.
3. Por qué S3 Vectors
Es un servicio nativo de AWS para indexar y consultar vectores. Para 400 vectores de 1024 dims:
- Latencia p50 < 50 ms.
- Costo despreciable (pay-per-query).
- Sin necesidad de operar Pinecone, Weaviate, Qdrant.
- Encaja naturalmente con el resto del stack (IAM, KMS, CloudWatch).
4. Por qué Lambda + API Gateway HTTP API
| Razón | Detalle |
|---|---|
| Costo en reposo | $0. Solo pagas por invocación. |
| Escala automática | De 0 a miles de RPS sin tocar nada. |
| Despliegue atómico | Cambiar el VECTOR_INDEX env var = "rollout" sub-segundo. |
| Compat con Bedrock | SDK de boto3 vendoreado en el zip. |
El uso de HTTP API (no REST API) reduce latencia y costo.
Flujo POST /classify
- API Gateway recibe JSON con
audio_base64,format,filename. - Lambda valida shape, decodifica base64, valida duración y peso.
- Bedrock recibe el audio y devuelve un embedding de 1024 dims.
- S3 Vectors consulta los
k=5vecinos más cercanos por distancia coseno. - Lambda aplica votación mayoritaria →
prediction.category. - DynamoDB guarda
request_id, timestamp, predicción, vecinos. - SNS publica si la urgencia es alta (no usado en demo público).
- Lambda devuelve la respuesta JSON.
Latencia objetivo: < 800 ms p95 desde el fetch del navegador hasta el 200 OK.
Estado de la infraestructura
| Recurso | Valor | Estado |
|---|---|---|
| Audio bucket | soundguard-dev-audio | 800 wavs (fold 1 + fold 2) |
| Vector bucket | soundguard-dev-vectors | activo |
| Production index | soundguard-dev-index | 400 vectores (fold 1), k=1, 92.0% |
| Staging index | soundguard-dev-staging | 400 vectores (fold 2), k=1, 90.0% |
| API endpoint | https://poi8bb5go9.execute-api.us-east-1.amazonaws.com | listo |
| DynamoDB | soundguard-dev-results | activa |
IaC
Toda la infra está en infra/*.tf con la convención una .tf por servicio:
infra/
├── main.tf # provider, backend
├── s3.tf # buckets de audio
├── s3vectors.tf # índice de producción
├── s3vectors_staging.tf # índice de staging
├── lambda.tf # función de inferencia
├── apigateway.tf # HTTP API + rutas
├── dynamodb.tf # logs de predicciones
├── pipeline_lambdas.tf # Lambdas del pipeline CT
├── iam.tf # roles de las funciones
├── iam_users.tf # usuarios humanos del equipo
├── outputs.tf # endpoint, índices, ARNs
└── variables.tf