Resultados
Comparativa de modelos, grid search de k, métricas finales y stack tecnológico.
Galería de figuras
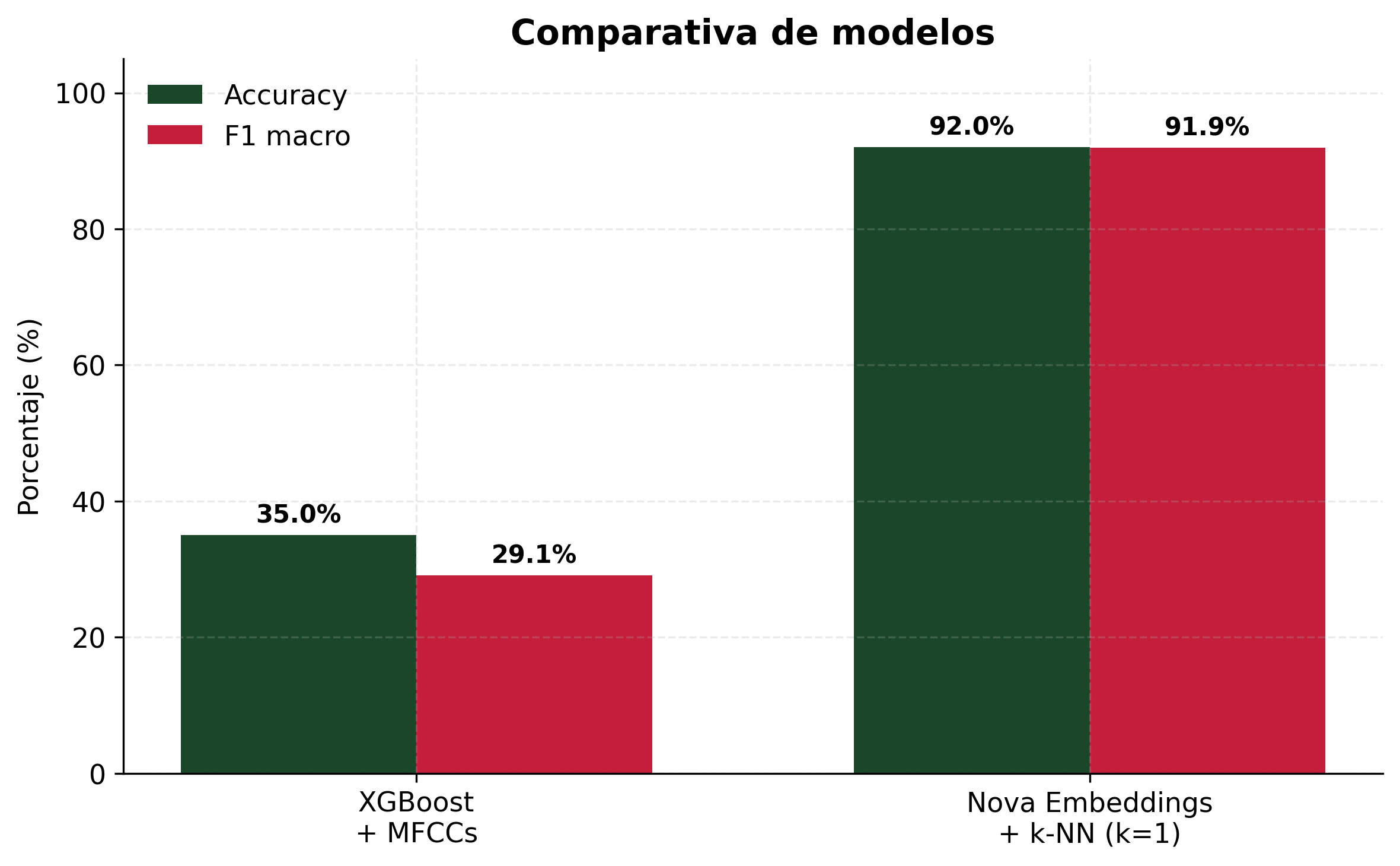 Figura 1. Accuracy y F1 macro: XGBoost + MFCCs (35.0% / 29.1%) vs k-NN + Nova (92.1% / 92.0%).
Figura 1. Accuracy y F1 macro: XGBoost + MFCCs (35.0% / 29.1%) vs k-NN + Nova (92.1% / 92.0%).
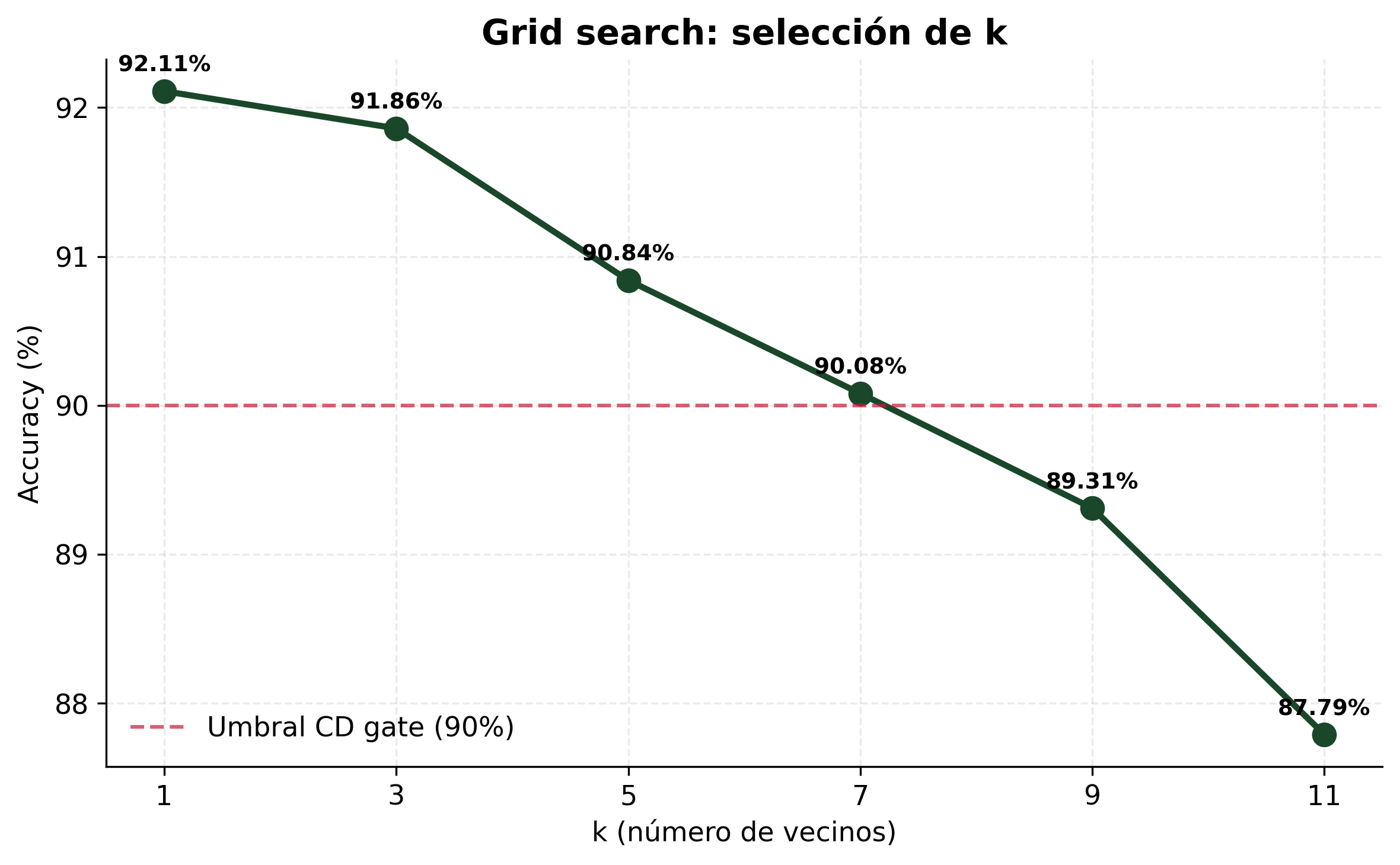 Figura 2. Grid search del hiperparámetro k. El óptimo es k=1 (92.11%); accuracy decrece monótonamente al aumentar k.
Figura 2. Grid search del hiperparámetro k. El óptimo es k=1 (92.11%); accuracy decrece monótonamente al aumentar k.
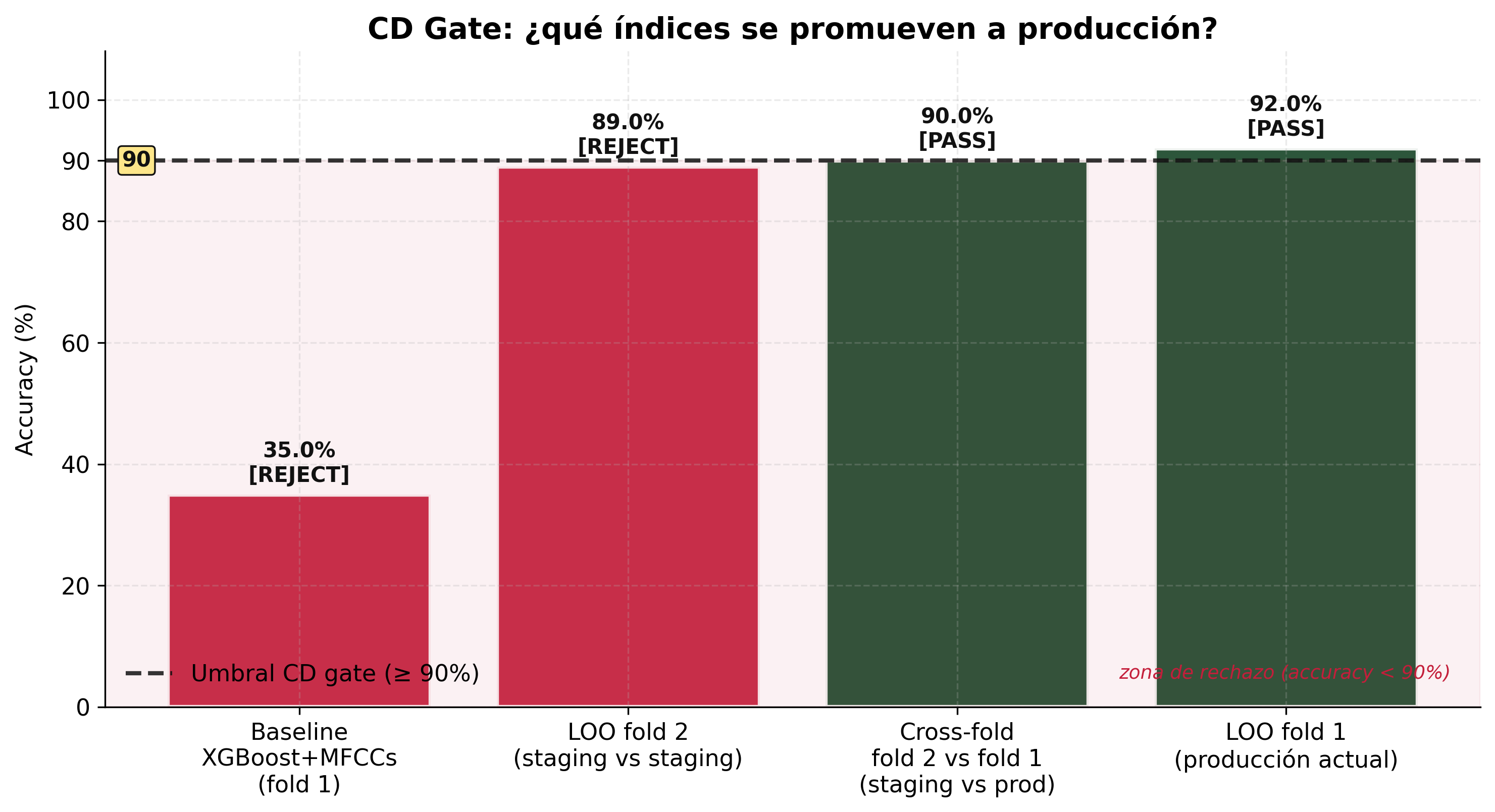 Figura 3. ¿Qué índices se promueven a producción? Sólo el cross-fold (90.0%) y el LOO de fold 1 (92.0%) superan el umbral. El baseline XGBoost (35%) y la evaluación interna del fold 2 (89%) son rechazadas.
Figura 3. ¿Qué índices se promueven a producción? Sólo el cross-fold (90.0%) y el LOO de fold 1 (92.0%) superan el umbral. El baseline XGBoost (35%) y la evaluación interna del fold 2 (89%) son rechazadas.
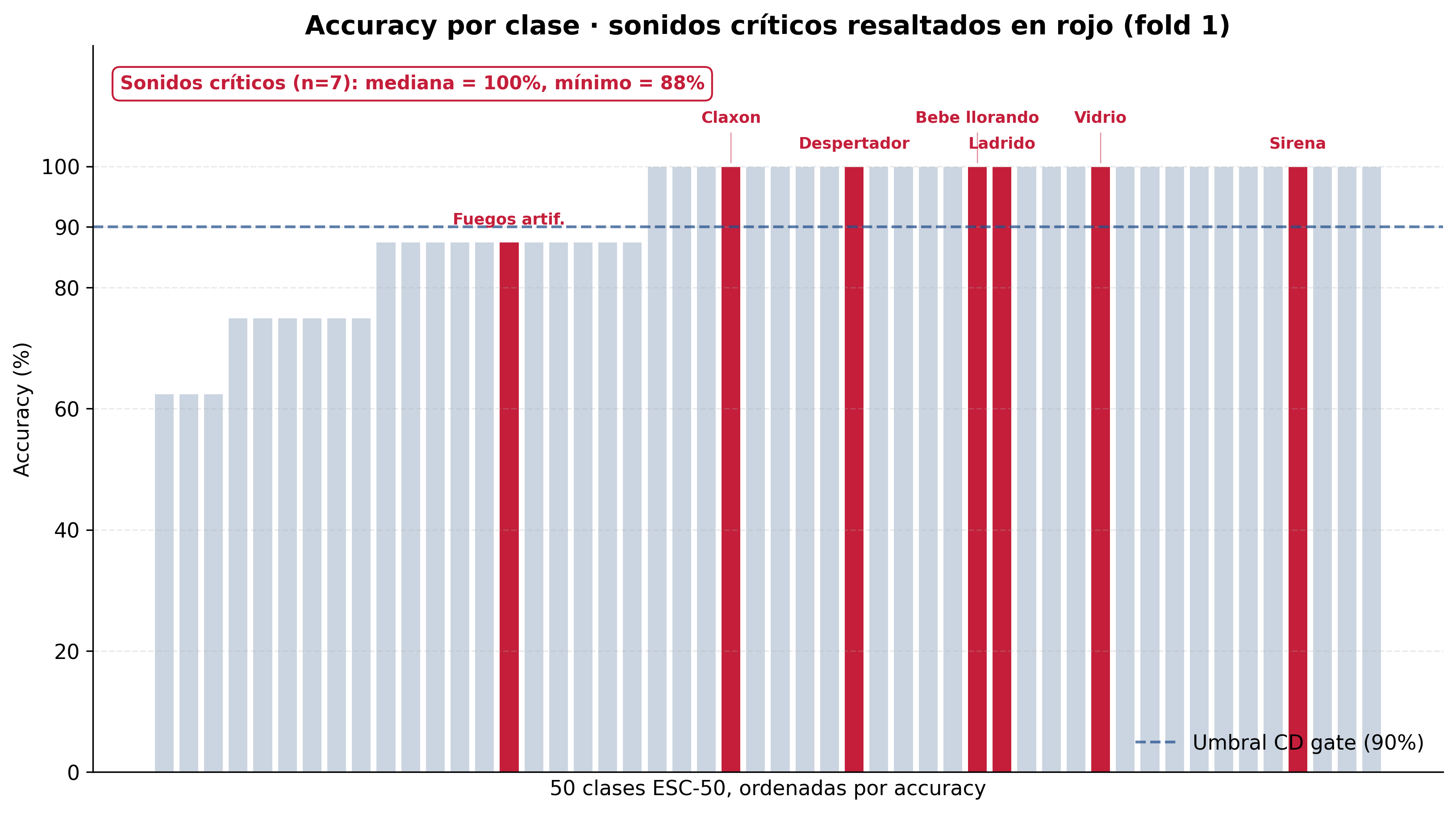 Figura 4. Accuracy por clase (50 clases ESC-50). Los 7 sonidos críticos (sirena, claxon, despertador, vidrio, llanto de bebé, fuegos artificiales, ladrido) en rojo: 6 alcanzan 100%; sólo "fuegos artificiales" baja a 88%.
Figura 4. Accuracy por clase (50 clases ESC-50). Los 7 sonidos críticos (sirena, claxon, despertador, vidrio, llanto de bebé, fuegos artificiales, ladrido) en rojo: 6 alcanzan 100%; sólo "fuegos artificiales" baja a 88%.
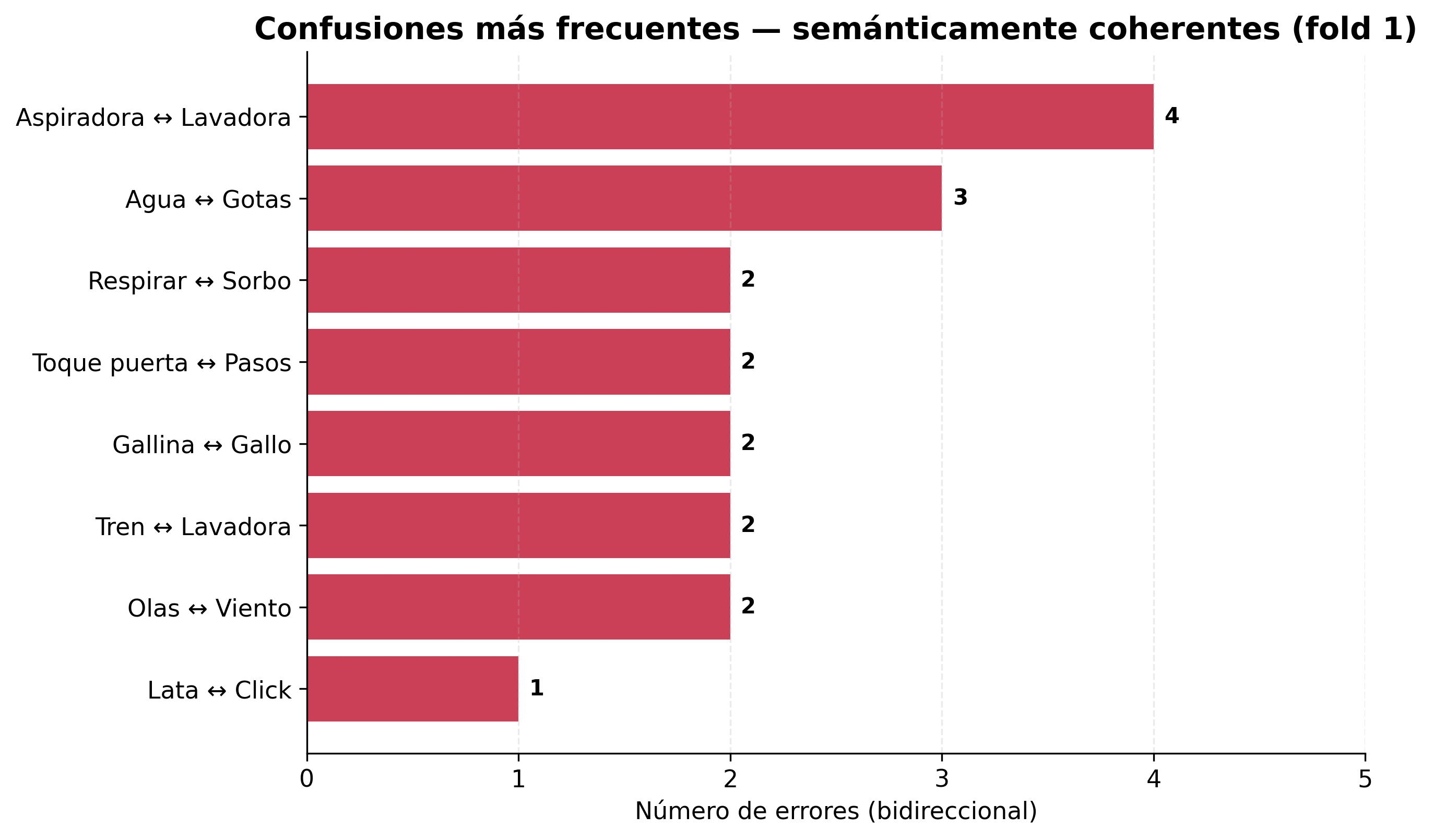 Figura 5. Pares más confundidos (fold 1, bidireccionales). Aspiradora ↔ lavadora, gallina ↔ gallo, agua ↔ gotas son acústicamente similares: el modelo falla con coherencia semántica.
Figura 5. Pares más confundidos (fold 1, bidireccionales). Aspiradora ↔ lavadora, gallina ↔ gallo, agua ↔ gotas son acústicamente similares: el modelo falla con coherencia semántica.
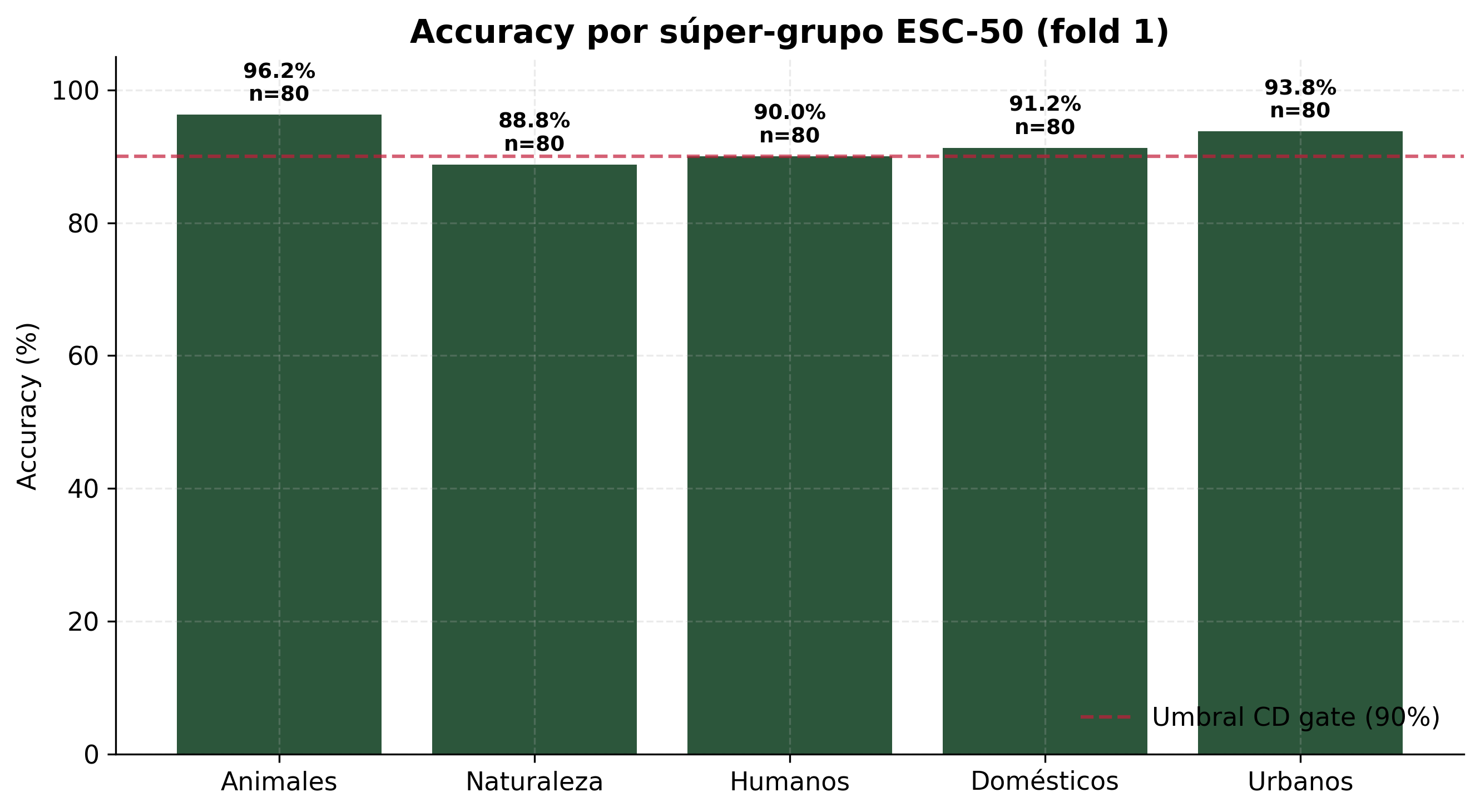 Figura 6. Accuracy por súper-grupo. El modelo es uniformemente fuerte en categorías estructuradas (animales 96.2%, urbanos 93.8%, domésticos 91.2%) y muestra mayor variabilidad en sonidos atmosféricos (naturaleza 88.8%).
Figura 6. Accuracy por súper-grupo. El modelo es uniformemente fuerte en categorías estructuradas (animales 96.2%, urbanos 93.8%, domésticos 91.2%) y muestra mayor variabilidad en sonidos atmosféricos (naturaleza 88.8%).
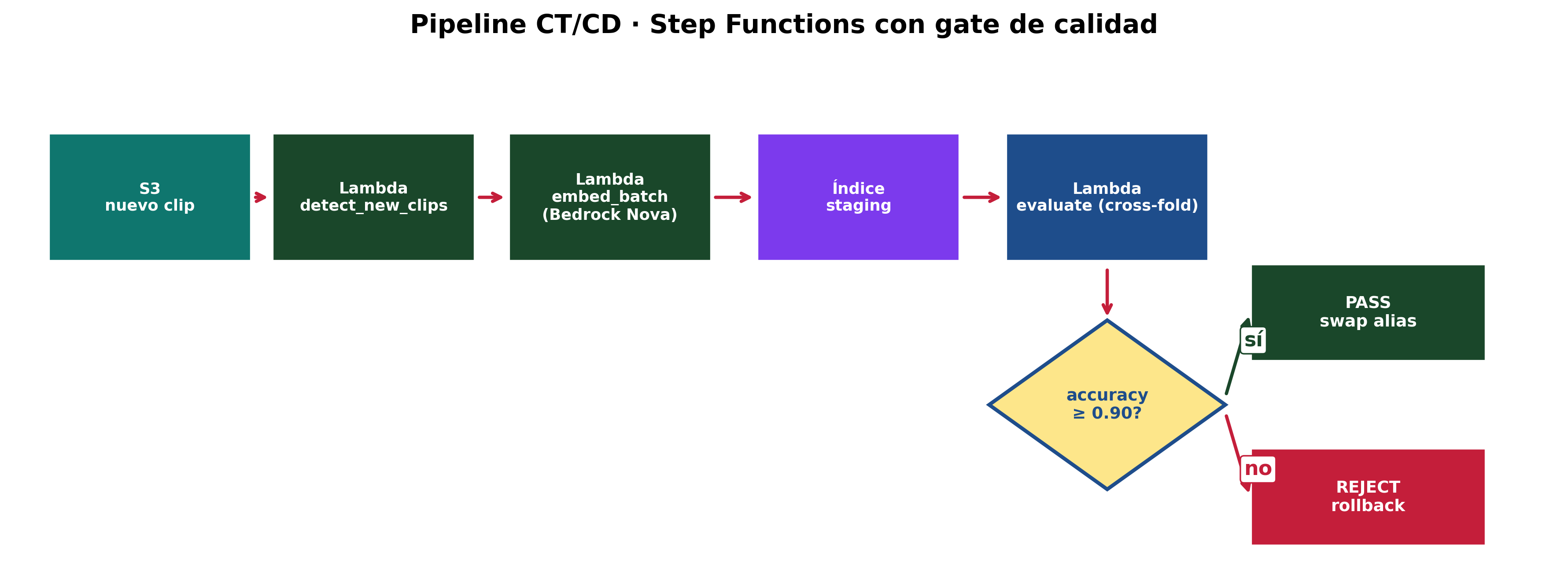 Figura 7. Pipeline de Continuous Training / Continuous Deployment automatizado en AWS Step Functions con gate de calidad (≥ 90% accuracy).
Figura 7. Pipeline de Continuous Training / Continuous Deployment automatizado en AWS Step Functions con gate de calidad (≥ 90% accuracy).
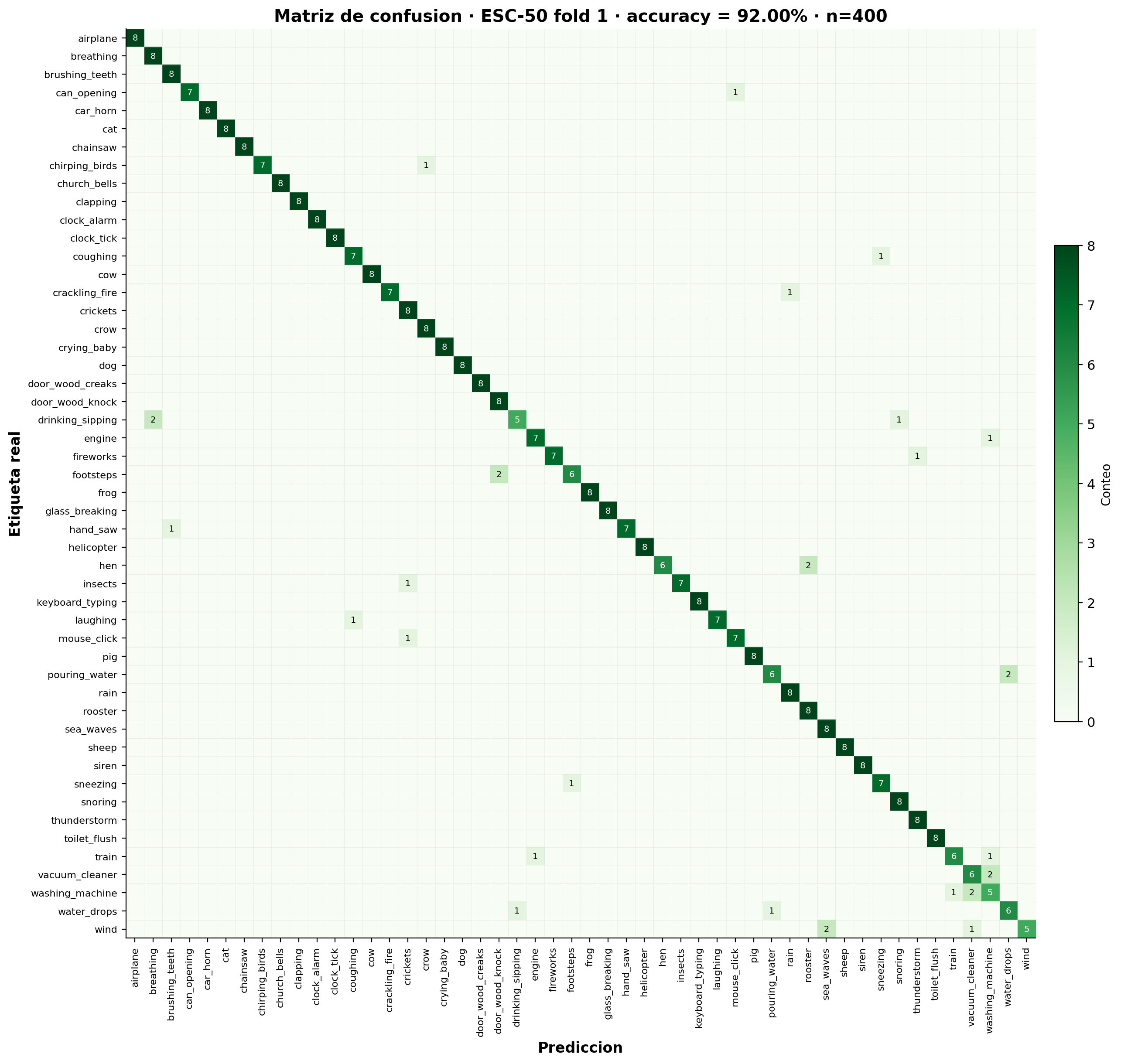 Figura 8. Matriz de confusión 50×50 sobre fold 1 (n = 400, k = 1). La diagonal dominante refleja el 92% de accuracy; los errores se concentran en pares acústicamente similares y son bidireccionales.
Figura 8. Matriz de confusión 50×50 sobre fold 1 (n = 400, k = 1). La diagonal dominante refleja el 92% de accuracy; los errores se concentran en pares acústicamente similares y son bidireccionales.
Comparativa de modelos
| Métrica | XGBoost + MFCCs | k-NN + Nova Embeddings (k=1) | Diferencia |
|---|---|---|---|
| Accuracy | 35.00% | 92.11% | +57.11 pts |
| F1 macro | 29.10% | 92.04% | +62.94 pts |
| F1 weighted | 29.63% | 92.10% | +62.47 pts |
| Tiempo de entrenamiento | ~5 min (CPU) | 0 min | −5 min |
| Nuevas clases | reentrenar completo | agregar ejemplos | — |
| Explicabilidad | caja negra | vecinos visibles | — |
Conclusión: los embeddings de un foundation model (Nova) superan ampliamente al feature engineering manual (MFCCs) + XGBoost, sin necesidad de entrenamiento.
Grid search del valor de k
| k | Accuracy | F1 macro | Notas |
|---|---|---|---|
| 1 | 92.11% | 92.04% | Óptimo. El vecino más cercano basta. |
| 3 | 91.86% | 91.52% | — |
| 5 | 90.84% | 90.42% | Valor usado originalmente. |
| 7 | 90.08% | 89.41% | — |
| 9 | 89.31% | 88.14% | — |
| 11 | 87.79% | 86.89% | Peor. Demasiado ruido. |
Insight: a mayor k, la accuracy baja. Los embeddings de Nova son tan discriminativos que incluir más vecinos introduce ruido de clases similares.
Cross-fold validation (CD gate)
| Escenario | Accuracy | F1 macro | Decisión |
|---|---|---|---|
| LOO: fold 2 vs fold 2 | 89.00% | 0.8888 | REJECT |
| Cross-fold: fold 2 vs fold 1 | 90.00% | 0.8949 | PASS |
El gate del 90% se supera con el escenario realista (queries de staging contra el índice de producción).
Stack tecnológico
| Capa | Servicios |
|---|---|
| Almacenamiento | S3 (audio raw), S3 Vectors (embeddings indexados) |
| Embeddings | Amazon Bedrock — Nova Multimodal Embeddings |
| Inferencia | AWS Lambda + API Gateway HTTP API |
| Persistencia | DynamoDB (logs de predicciones) |
| Orquestación | AWS Step Functions (CT pipeline) |
| Tracking | MLflow (experimentos, grid search) |
| Infra | Terraform (IaC) |
| Frontend (docs) | Next.js 16 + Fumadocs (este sitio), desplegado en Cloudflare |
| Demo | HTML + Tailwind CSS + JavaScript vanilla |
| Baseline | XGBoost + librosa MFCCs (comparativa) |
Entregables
- Pipeline end-to-end funcional (ingesta + inferencia)
- Evaluación con métricas (accuracy, F1, confusion matrix)
- Comparativa de modelos (XGBoost vs embeddings)
- Experiment tracking (MLflow + grid search)
- CI/CD: staging + CD gate con threshold del 90%
- CT: Step Functions pipeline automatizado
- Demo interactivo (drag & drop + micrófono)
- Documentación técnica (este sitio)
- Infra como código (Terraform completo)
- Accesibilidad / impacto social (app para discapacidad auditiva)
Reproducibilidad
# Setup
make setup-ingestion
# Deploy infra
cd infra && terraform apply -auto-approve
# Ingesta
make upload # sube fold 1 a S3
make ingest # genera embeddings
# Evaluación
python -m src.evaluation.evaluate_knn --fold 1 --mlflow
# Cross-fold (staging vs producción)
python -m src.evaluation.evaluate_cross_fold --query-fold 2 --ref-fold 1 --k 1
# Baseline comparativo
python -m src.baseline.extract_mfccs --fold 1
python -m src.baseline.train_xgboost --fold 1
# CD gate
python -m src.pipeline.promote_index --threshold 0.90 --mlflow
# Step Functions
aws stepfunctions start-execution \
--state-machine-arn "$(cd infra && terraform output -raw stepfunctions_arn)" \
--input '{"fold":1}'
# MLflow UI
mlflow ui --backend-store-uri "file://$(pwd)/mlruns"Referencias
- Piczak, K. J. (2015). ESC: Dataset for Environmental Sound Classification. ACM Multimedia. https://github.com/karolpiczak/ESC-50
- Salamon, J. et al. (2014). UrbanSound8K: A Dataset and Taxonomy for Urban Sound Research. ACM Multimedia.
- AWS — Amazon Nova Multimodal Embeddings (Bedrock).
- AWS — S3 Vectors.